import re import urllib.request import sys,os # 获取网页html def getHtml(url) : op = urllib.request.urlopen(url) html = str(op.read()) op.close() return html # 正则获取图片地址 def getImg(html): #reg = r'src=".*\.jpg"' reg = r'<img src="(.*?\.jpg)"' imgre = re.compile(reg) return imgre.findall(html, re.M) # 下载图片 def downloadImg(urls, tempPath='d://img/'): index = 0 # 判断文件夹是否存在 if os.path.isdir(tempPath) == False: os.mkdir(tempPath) # 下载 for url in urls: print('正在下载:' + url) fileName = tempPath + str(index) + '.jpg' urllib.request.urlretrieve(url, fileName) index += 1 # 开始啦 html = getHtml("http://www.shuoeasy.com/blog/") imgs = getImg(html) downloadImg(imgs)
你可能感兴趣的文章
热门文章
-
 windows下软链接mklink
windows下软链接mklink阅读: 23144
-
-
python入门-读取文件并记住位置
阅读: 19937 评论:1
-
-
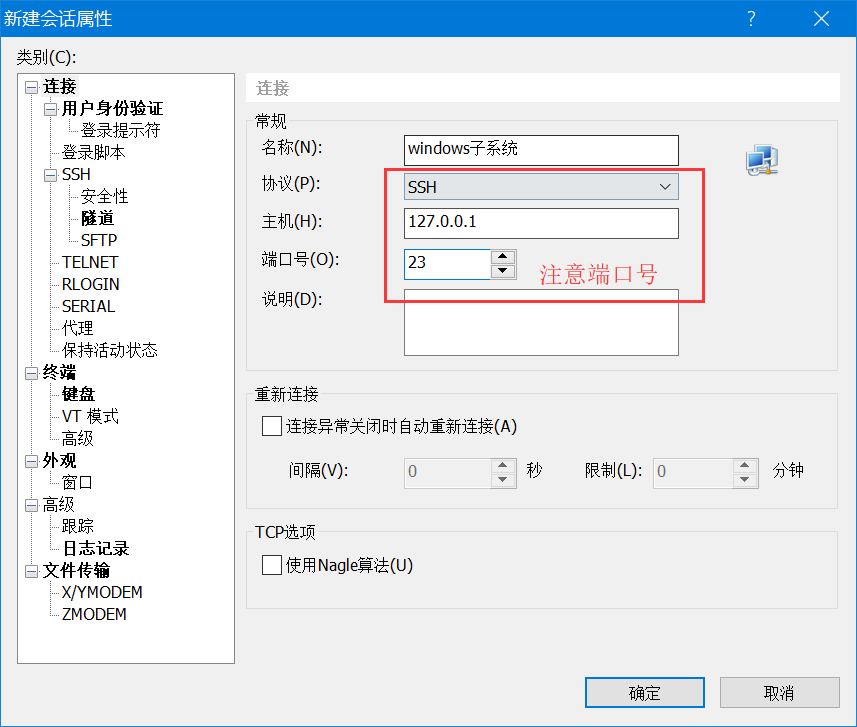 使用ssh链接windows子系统(Ubuntu)
使用ssh链接windows子系统(Ubuntu)阅读: 18361
-
Linux常用命令
阅读: 18228
